Copulas for Finance a Reading Guide and Some Applications
Introduction
The study of the copula functions is very relevant because of their implementation in the field of financial portfolio risk management. The copula functions are used in financial applications since 2000, following the seminal researches of [1, 2]. The crucial matter is the real distribution of financial data. Empirical evidence has widely proved that the multinormal distribution is inadequate to model portfolio's financial asset returns distribution at least from two points of view:
(1) The empirical marginal distributions are skewed and fat-tailed.
(2) The normal distribution does not consider the possibility of extreme joint co-movements for financial asset returns.
In other words, the real dependence structure of the financial assets is different from the Gaussian one and especially under situations of market stress [3]. For this reason, the copula functions can be a useful and simple tool for implementing efficient algorithms and to simulate the financial asset returns distribution more realistically.
The copulas allow us to model the dependence structure independently from the marginal distributions. In this way, we may construct a multivariate distribution with different margins and the dependence structure given from a particular type of copula function. Therefore, a crucial step in this context is the choice and the calibration of the most adequate copula function from the real financial data.
In this paper, a group of useful methods for calibrating, selecting, and simulating copula functions is presented. We aim to collect and to describe in a very simple manner the principal contributions in this field provided by the most famous and accredited international literature (for example [4–18]). In our opinion, the study of copula functions is very important because these quantitative tools are valuable for developing advanced financial portfolio models. Potential applications are in the field of market, credit, and operational risks. In particular, the copula functions can model the dependence structure between risk factors (for example, equity returns, interest rate returns, and foreign exchange returns) in a more reliable way.
In particular, the credit assets clearly show a non-normal return distribution and the phenomena of asymmetry, leptokurtosis, and tail dependence. To take into account these empirical characteristics of credit asset return distributions, with particular regard to multiple default events, we may model the default dependence structure by using different types of copulas. Technically, the times until default of each obligor in the loan portfolio may be simulated following a copula-based approach first illustrated in Li [1].
The copula functions have been also applied in the field of portfolio credit asset allocation where the optimal portfolio composition [19] may change by utilizing various types of the copula. The crucial aspect is the choice of the kind of copula better describing the default dependence structure of credit assets in a portfolio (see, for example [20]).
Further applications of copula functions in the financial risk management have been also developed by [21–25]. Nowadays, the copula functions find a precious application also in the estimate of the systemic risk generated by the Systemically Important Financial Institutions (see, for example [26–28]).
The implications in the field of the macro-prudential regulation on the global financial system are evident [29, 30].
Finally, in this paper, the described statistical methods for calibrating, selecting, and simulating copula functions are implemented to an empirical financial data set concerning the log-returns of two Italian equities: Olivetti and TIM. When it is possible, we show as the copula approach performs better than the bivariate normal distribution in modeling the real financial data.
The paper is structured as follows. In Definition of the Copula Function Section, a brief definition of copula function is given, describing the main families of copulas utilized in financial practical applications1. In Parameter Estimation of a Given Copula Section, some quantitative approaches to estimate the parameters of a determined copula function from real data are presented. The procedures for selecting the type of copula function which better fits empirical data are shown in Selecting the Right Copula Section. In Simulation Algorithms Section, the algorithms to simulate random variates from some types of copula are illustrated. An application to a time series of the log-returns for two Italian equities is performed in Application to Two Italian Equities Section. Finally, in Concluding Remarks section, we draw some concluding remarks.
Definition of the Copula Function
An n-dimensional copula2 is a multivariate distribution function (d.f.) C, with uniform distributed margins in [0, 1] (U(0, 1)) and the following properties:
1. C: [0, 1]n → [0, 1];
2. C is grounded and n-increasing;
3. C has margins Ci which satisfy Ci(u) = C(1, … , 1, u, 1, … , 1) = u for all u ∈ [0, 1].
It is obvious, from the above definition, that if F1, … , Fn are univariate distribution functions, C(F1(x1), … , Fn(xn)) is a multivariate d.f. with margins F1, …, Fn, because Ui = Fi(Xi), i = 1, … , n, is a uniform random variable. Copula functions are a useful tool to construct and simulate multivariate distributions.
The following theorem is known as Sklar's Theorem [31, 32]. It is the most important theorem about copula functions because it is used in many practical applications.
Theorem 3: Let F be an n-dimensional d.f. with continuous margins F 1,…, F n . Then it has the following unique copula representation:
From Sklar's Theorem we see that, for continuous multivariate distribution functions, the univariate margins and the multivariate dependence structure can be separated. The dependence structure can be represented by a proper copula function. Moreover, the following corollary is attained from (1).
Corollary: Let F be an n-dimensional d.f. with continous margins F 1 ,…, F n and copula C (satisfying(1)). Then, for any u = (u 1,…, u n ) in [0, 1] n :
where F i −1 is the generalized inverse of F i .
A trivial example is the copula of independent random variables (the product copula). It takes the following form:
Another example is the Farlie–Gumbel–Morgenstern (FGM) copula, which in the bivariate case is defined by:
Elliptical Copulas
The class of elliptical distributions provides useful examples of multivariate distributions because they share many of the tractable properties of the multivariate normal distribution. Furthermore, they allow modeling multivariate extreme events and forms of non-normal dependencies. Elliptical copulas are simply the copulas of elliptical distributions. Simulation from elliptical distributions is easy to perform. Therefore, as a consequence of Sklar's Theorem4, the simulation of elliptical copulas is also easy.
Normal Copula
The Gaussian (or normal) copula is the copula of the multivariate normal distribution. The random vector X = (X1, …, Xn) is multivariate normal iff:
(1) The univariate margins F1, …, Fn are Gaussians;
(2) The dependence structure among the margins is described by a unique copula function C (the normal copula) such that5:
where
If n = 2, Eq. 3 can be written as:
where R 12 is simply the linear correlation coefficient between the two random variables.
t-Student Copula
The copula of the multivariate t-Student distribution is the t-Student copula. Let X be a vector with an n-variate t-Student distribution with
where
The copula of vector X is the t-Student copula with
where
For n = 2, the t-Student copula has the following analytic form:
where R12 is the linear correlation coefficient of the bivariate t-Student distribution with
Archimedean Copulas
An Archimedean copula can be written in the following form:
for all
i.
ii. for all
iii.for all
Examples of bivariate Archimedean copulas are the following:
Product Copula
Clayton Copula9
Gumbel Copula10
Frank copula11
Extensions to the multivariate case are the following:
Cook–Johnson Copula12
Gumbel–Hougaard Copula
Frank Copula
Parameter Estimation of a Given Copula
The Maximum Likelihood (ML) Method
Let f be the density of the joint distribution F:
where fi is the univariate density of the marginal distribution Fi and c is the density of the copula given by the following expression:
We suppose a set of T empirical data of n financial asset log-returns,
The ML estimator
The Method of Inference Functions for Margins (IFM)
According to the IFM method13, the parameters of the marginal distributions are estimated separately from the parameters of the copula. In other words, the estimation process is divided into the following two steps:
i. Estimating the parameters
where l i is the log-likelihood function of the marginal distribution Fi;
Estimating the copula parameters
where l c is the log-likelihood function of the copula.
The Canonical Maximum Likelihood (CML) Method
The CML method differs from the IFL method because no assumptions are made about the parametric form of the marginal distributions. The estimation process is performed in two steps:
i. Transforming the dataset
ii. Estimating the copula parameters as follows:
For example, we can estimate the parameter R of the Gaussian copula (Eq. 3) with the CML or the IFM method in the following way15:
where
The following recursive procedure16 is used to estimate the parameter R of the tν-Student copula (Eq. 5):
i. Let
ii.
where
iii. Step (ii) is repeated until
Mashal and Zeevi [37] suggest using the following algorithm to estimate the parameters
i. Transforming the dataset
ii. Estimate
iii. Perform a numerical search for
Parameter Estimation and Dependence Measures
This method works only with one-parameter bivariate copulas. The main dependence measures17 can be written as a function of the copula [15]. In some cases analytical solutions are available and the copula parameter can simply be written as a function of the dependence measure. Otherwise, a numerical procedure is necessary.
For instance, for the Gaussian copula we obtain:
For the Clayton copula:
For the Gumbel copula:
For the Morgenstern copula:
Non-parametric Estimation
So far, the parameters of a given type of copula are been estimated. Now the empirical copula (or the Deheuvels copula [38]) is constructed from the sample data. This is any copulas of the empirical multivariate distribution.
Let
Any Function
defined on the lattice
The empirical copula density [15] has the following expression:
Selecting the Right Copula
In Parameter Estimation of a Given Copula Section, some methods to calibrate the parameters of a given analytical representation of copula function are illustrated. Now the issue is selecting the type of copula function which fits better the empirical data.
Selecting an Archimedean Copula
The method described in this section (see [13]) can select the Archimedean copula which fits better real data. An Archimedean copula has the analytical representation given by Eq. 6. So, to select the copula, it is sufficient to identify the generator,
In the bivariate case (n = 2), Genest and Rivest [13] defined a univariate function, K, which is related to the generator of the Archimedean copula through the following expression:
A non parametric estimation of (9) is the following:
where
We choose a parametric representation for the generator,
The parameter
All the steps described above are repeated for different choices of the generator
The optimal copula may also be selected by minimizing the distance based on the L2 norm between Eqs. 9 and 10:18
The method described in this section may also be used to graphically estimate the parameter
Selecting the Right Copula Using the Empirical Copula
Let
The distance (Eq. 11) may also be used to estimate the vector of parameters
Simulation Algorithms
In this section, we show a collection of algorithms to simulate random variates (u1, … , un) from certain types of copula C. For the definition of the copula, these random variates ui are a determination of correlated uniform(0,1) distributed random variables. So, to simulate random variates (x1, … ,xn) from a multivariate distribution F with given margins Fi, i = 1, … ,n, and copula C, we have to invert each ui using the marginal distributions:
Simulation From the Gaussian Copula
To generate random variates from the Gaussian copula (Eq. 3), we can use the following procedure. If the matrix R is positive definite, then there is some
The matrix A can be easily determined with the Cholesky decomposition of R. This decomposition is the unique lower-triangular matrix L such as LLT = R. Hence, one can generate random variates from the n-dimensional Gaussian copula running the following algorithm:
Find the Cholesky decomposition A of the matrix R;
Simulate n independent standard normal random variates z = (z1,…, zn)T;
Set x = Az;
Determine the components
The vector (u1, … , un)T is a random variate from the n-dimensional Gaussian copula,
Simulation From the tν-Student Copula
To simulate random variates from the t-Student copula (5),
Find the Cholesky decomposition, A, of R;
Simulate n independent random variates z = (z1, … , zn)T from the standard normal distribution;
Simulate a random variate, s, from
Determine the vector y = Az;
Set
Determine the components
The resultant vector is: (u1,…, un)T ∼
Simulation From the Cook–Johnson Copula
This algorithm is a particular case of the one suggested by [39] for the generation of multivariate outcomes from a compound copula. To generate random variates from the Cook–Johnson copula with a parameter
Generate n independent random variates, y1, …, yn from the exponential distribution19 with parameter
Generate a random variate, z, from a Gamma
Set
The vector u=(u1, … ,un) is generated from the Cook–Johnson copula.
The Cook–Johnson copula reproduces a positive dependence structure. A negative dependence structure may be obtained for some of the variables by setting
Simulation From the Morgenstern Copula
The following algorithm [40] generates bivariate random variates from the Farlie–Gumbel–Morgenstern copula:
Generate independent uniform(0,1) random variates v1 and v2;
Set u1 = v1;
Calculate
Set
The vector (u1, u2) is generated from the Farlie–Gumbel–Morgenstern copula.
A General Algorithm to Simulate a Copula
This method is based on the conditional distributions of a random vector U = (U1, … , Un). In the bivariate case, we have:
where
The Algorithm20 is the Following:
Generate two independent uniform(0,1) random variates v1 and v2;
Set u1 = v1;
Let C(u2;u1) = C2\1(u1, u2). Set u2 = C−1(v2;u1);
The vector (u1,u2) is generated from the copula C.
For instance, for the bivariate Frank copula, we have:
and
The above algorithm may be generalized to the multivariate case:
Generate n independent uniform(0,1) random variates, (v1,…, vn);
Set u1 = v1;
let C(um;u1,…, um-1) = Cm\1,…,m-1(u1,…, um), m = 2,…, n, where
Set um = C−1(vm;u1,…, um-1), m = 2,…, n;
The vector (u1,…, un) is generated from the copula C.
This algorithm is computationally intensive for high values of n. It is a difficult issue to compute the conditional distribution (12).
Simulation From the Empirical Copula
The below algorithm permits to generate a vector of random variates from the empirical copula (Eq. 8):
Randomly draw a complete observation vector
Using the empirical distribution functions,
(u1,…, un) is a vector of non-independent uniforms(0, 1) that are dependent through the empirical copula.
Application to Two Italian Equities
In this section, we apply the methods of copula function calibration and simulation described before. We use a dataset of 1,012 daily observations of the log-returns of two Italian equities: TIM and Olivetti. In Table 1, the principal statistics regarding the two Italian equities are reported. In Figure 1, we plot the empirical standardized log-returns of TIM against the standardized log-returns of Olivetti.

TABLE 1. Main statistics of the empirical distribution of the log-returns of TIM and Olivetti.
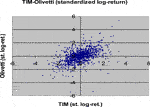
FIGURE 1. Plot of the empirical standardized log-returns TIM/Olivetti.
We have estimated, with the CML method, the parameters of different types of the bivariate copula, using the dataset of 1,012 historical daily log-returns observations. In this way, we do not consider any particular analytical form for the marginal distributions, and only the copula effects are taken into account.
Therefore, we have selected the copula which better approximates the empirical copula using the L2 norm (Eq. 11). The results are shown in Table 2.

TABLE 2. CML estimation of the parameters (α or R12) and calculation of the L2 norm for different copula types.
Observing the results in Table 2, the t10-Student copula seems to be the one that better approximates the empirical copula of the dataset. However, the difference between the t10-Student copula and the Normal copula is very low. So the Gaussian copula could be appropriate. We remember that the use of the Gaussian copula permits us to construct algorithms to simulate scenarios from a multivariate distribution with different margins. The commonly used multivariate Normal is only a particular case where all the margins are Gaussians too.
The simulation algorithms shown in Selecting the Right Copula Section are applied for simulating 1,000 scenarios for the standardized log-returns of the equities TIM and Olivetti, using the parameter estimations in Table 2. In all the cases, we have used standardized Gaussian margins, because our aim is only to compare the different copulas. In Figures 2–8 we have plotted the results.
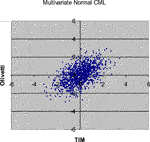
FIGURE 2. 1,000 Monte Carlo simulations of bivariate random variates (x 1, x 2) with Gaussian copula (R 12 = 0.53248) and standard normal margins.
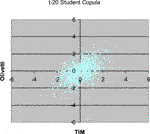
FIGURE 3. 1,000 Monte Carlo simulations of bivariate random variates (x 1, x 2) with t 20-Student copula (R 12 = 0.53564) and standard normal margins.
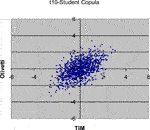
FIGURE 4. 1,000 Monte Carlo simulations of bivariate random variates (x 1, x 2) with t 10-Student copula (R 12 = 0.54037) and standard normal margins.
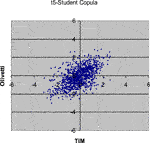
FIGURE 5. 1,000 Monte Carlo simulations of bivariate random variates (x 1, x 2) with t 5-Student copula (R 12 = 0.53953) and standard normal margins.
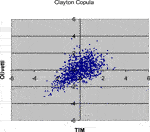
FIGURE 6. 1,000 Monte Carlo simulations of bivariate random variates (x 1, x 2) with Clayton copula (α = 1.12436) and standard normal margins.
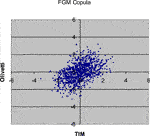
FIGURE 7. 1,000 Monte Carlo simulations of bivariate random variates (x 1, x 2) with Farlie-Gumbel-Morgenstern copula (α = 1.55349) and standard normal margins.
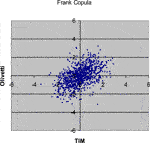
FIGURE 8. 1,000 Monte Carlo simulations of bivariate random variates (x 1, x 2) with Frank copula (α = 3.82211) and standard normal margins.
Comparing the plots in the above Figures with the empirical distribution obtained from the historical data and represented in Figure 1, we can see some differences. These deviations may be caused by an inadequate choice of the margins21. Our aim was only to compare different types of copulas without assumptions about the analytical form of the marginal distributions.
Concluding Remarks
This paper is a brief review of the existing methodologies for calibrating, choosing, and simulating different types of copula functions. The described methods are applied to a historical log-returns dataset of two Italian equities. We have seen how copula functions are a useful tool for implementing efficient simulation algorithms. Practical algorithms for generating Monte Carlo scenarios from a multivariate distribution with a fixed copula and different margins are easily implemented to simulate financial asset returns. The traditional models use the multinormal distribution22 to simulate asset log-returns. We can choose different marginal distributions for building more efficient algorithms also using a normal copula. The choice of the margins seems to have a more significant impact than the choice of the type of the copula on the results of the simulation. In this paper, only the copula effects are taken into account.
As clearly underlined in the paper, the application to a return time series of two Italian equities has only a demonstrative scope. The copula functions may be implemented to a portfolio of n financial assets traded on different stock markets such as the American, European and Asian ones.
In the field of portfolio risk management, the copula functions are precious tools for developing advanced financial risk measurement models. Traditionally, these quantitative instruments have been utilized for measuring more adequately the market, credit, and operational risks of financial institutions. Successively, copula functions have been also implemented in the field of the integrated measurement of the different financial risks by modeling the dependence structure among the market, credit, and operational losses. Currently, the copula functions are used for estimating the marginal contribution of each financial institution to the systemic risk, that is the instability of the global financial system. The implications in terms of macro-prudential policy and supervisory choices on financial institutions are evident.
Data Availability Statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1i.e.: the class of the elliptical copulas and the class of the Archimedean copulas.
2The original definition is given by Sklar (1959) [31–33].
3For the proof, see Sklar (1996) [32].
4See Eqs. 1 and 2.
5As one can easily deduce from (Eq. 2).
6If
7 Y has an n-dimensional normal distribution with mean vector 0 and covariance matrix R.
8All the margins are equally distributed.
9Clayton (1978) [33].
10Gumbel (1960) [34], Hougaard (1986) [35].
11Frank (1979) [36].
12It is a multivariate extension of the Clayton copula.
13Joe and Xu (1996) [13].
14In other words, the variates
15See [7].
16See [4].
17i.e. the rank correlation coefficients: the Spearman's rho, ρ S, and the Kendall's tau, τ.
18See [7].
19The exponential distribution has the following form:
20Introduced by [12].
21Standardized Gaussians.
22i.e. Gaussian copula and margins.
References
2. Embrechts, P, McNeil, AJ, and Straumann, D. Correlation and dependence in risk management: properties and pitfalls In MAH Dempster, editor. Value at risk and beyond. Cambridge, UK: Cambridge University Press (2002). p. 176–223.
CrossRef Full Text | Google Scholar
3. Alexander, C. Market models: a guide to financial data analysis. London: Wiley (2001).
4. Bouyé, E, Durrleman, V, Nikeghbali, A, Riboulet, G, and Roncalli, T. Copulas for finance—a reading guide and some applications, Groupe de Recherche Opérationnelle, Crédit Lyonnais, Working Paper (2001).
Google Scholar
5. Bouyé, E, Durrleman, V, Nikeghbali, A, Riboulet, G, and Roncalli, T. Copulas: an open field for risk management. Groupe de Recherche Opérationnelle, Crédit Lyonnais, Working Paper (2000).
Google Scholar
6. Cook, RD, and Johnson, ME. A family of distributions for modeling non-elliptically symmetric multivariate data, J R Stat Soc B (1981). 43:210–8. doi:10.1111/j.2517-6161.1981.tb01173.x
CrossRef Full Text | Google Scholar
7. Durrleman, V, Nikeghbali, A, and Roncalli, T. Which copula is the right one?, Groupe de Recherche Opérationnelle, Crédit Lyonnais, Working Paper (2000).
Google Scholar
8. Embrechts, P, Hoeing, A, and Juri, A. Using copulae to bound the Value-at-Risk for functions of dependent risks, Finance and Stochastics, New York: Springer (2003).
9. Embrechts, P, Lindskog, F, and McNeil, AJ. Modelling dependence with copulas and applications to risk management. In: "Handbook of heavy-tailed distributions in finance, Chapter 8", S Rachev, editor. Amsterdam: Elsevier (2003). p. 329–84.
CrossRef Full Text | Google Scholar
10. Frees, EW, and Valdez, EA. Understanding relationships using copulas, North Am Actuarial J. (1998). 2:1–25. doi:10.1080/10920277.1998.10595667
CrossRef Full Text | Google Scholar
11. Frey, R, and McNeil, AJ (2001). Modelling dependent default, ETH Zurich preprint.
Google Scholar
12. Genest, C, and MacKay, J. The joy of copulas: bivariate distributions with uniform marginals. Am Stat (1986). 40:280–3. doi:10.2307/2684602
CrossRef Full Text | Google Scholar
13. Genest, C, and Rivest, L-P. Statistical inference procedures for bivariate Archimedean copulas, J Am Stat Assoc (1993). 88:1034–43. doi:10.1080/01621459.1993.10476372
CrossRef Full Text | Google Scholar
14. Joe, H, and Xu, JJ. The estimation method of inference functions for margins for multivariate models. Department of statistics, University of British Columbia, Technical Report N (1996).
Google Scholar
15. Nelsen, R. An introduction to Copulas. New York: Springer (1998).
16. Oakes, D. (1982). A model for association in bivariate survival data. J R Stat Soc B 44:414–22. doi:10.1111/j.2517-6161.1982.tb01222.x
CrossRef Full Text | Google Scholar
17. Roncalli, T. Gestion des Risques Multiples, Cours ENSAI de 3ème année, Groupe de Recherche Opérationnelle, Crédit Lyonnaise (2002).
Google Scholar
18. Wang, SS. Aggregation of correlated risk portfolios: models & algorithms, CAS Committee on Theory of Risk, Working Paper (1999).
Google Scholar
20. Di Clemente, A, and Romano, C. Measuring and optimizing portfolio credit risk: a copula-based approach. Econ Notes by Banca Monte dei Paschi di Siena SpA (2004). 33(no. 3):325–57. doi:10.1111/j.0391-5026.2004.00135.x
CrossRef Full Text | Google Scholar
21. Breymann, W, Dias, A, and Embrechts, P. Dependence structures for multivariate high-frequency data in finance. Q. Finance (2003). 3(2):1–14. doi:10.1080/713666155
CrossRef Full Text | Google Scholar
22. Daul, S, De Giorgi, E, Lindskog, F, and McNeil, AJ. The grouped t-copula with an application to credit risk. Risk (2003). 16:73–6.
Google Scholar
23. Cherubini, U, Luciano, E, and Vecchiato, W. Copula methods in finance. New York: John Wiley (2004).
CrossRef Full Text
24. Demarta, S, and McNeil, AJ. The t Copula and related Copulas, working paper. Zurich: ETH Zentrum (2004).
25. Bouyé, E, and Salmon, M. Dynamic copula quantile regressions and tail area dynamic dependence in Forex markets. Eur J Finance (2009). 15:721–50. doi:10.1080/13518470902853491
CrossRef Full Text | Google Scholar
26. Hakwa, B, Jager-Ambrozewicz, M, and Rudiger, B. Analysing systemic risk contribution using a closed Formula for conditional valueat-risk through copula. Commun Stoch Anal (2015). 9(1):131–58. doi:10.31390/cosa.9.1.08
CrossRef Full Text | Google Scholar
27. Karimalis, EN, and Nomikos, NK. Measuring systemic risk in the European banking sector: a Copula CoVaR approach. Eur J Finance (2018). 24(11):944–75. doi:10.1080/1351847x.2017.1366350
CrossRef Full Text | Google Scholar
28. Di Clemente, A. Estimating the marginal contribution to systemic risk by a CoVaR-model based on copula functions and ExtremeValue Theory. Finance Monet Econ (2018). 47(1):69–112. doi:10.1111/ecno.12095
CrossRef Full Text | Google Scholar
29. Gauthier, C, Lehar, A, and Souissi, M. Macroprudential capital requirements and systemic risk. J Financial Intermediation (2012). 21(4):594–618. doi:10.1016/j.jfi.2012.01.005
CrossRef Full Text | Google Scholar
30. Di Clemente, A. Comparing different systemic risk measures for European banking system. Int Bus Res (2019). 12:35–53.
Google Scholar
31. Sklar, A. Fonctions de répartition à n dimensions et leurs marges. Publications de l'Institut de Statistique de l'Université de Paris (1959). 8:229–31.
Google Scholar
32. Sklar, A. (1996). : Random variables, distribution functions, and copulas – a personal look backward and forward, in Distributions with fixed marginals and related topics, ed. By L Rüschendorff, B Schweizer, and M Taylor. Hayward, CA: Institute of Mathematical Statistics, pp. 1–14.
CrossRef Full Text
33. Clayton, DG. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika (1978). 65:141–51. doi:10.1093/biomet/65.1.141
CrossRef Full Text | Google Scholar
36. Frank, MJ. On the simultaneous associativity of F(x, and x+y-F(x,y). Aequationes Mathematicae (1979). 19:194–226. doi:10.1007/bf02189866
CrossRef Full Text | Google Scholar
37. Mashal, R, and Zeevi, A. "Beyond Correlation: extreme Co-movements between financial assets". Working Paper: Columbia University (2002).
38. Deheuvels, P. La fonction de dépendance empirique et ses propriétés – un test non paramétrique d'indépendance. Académie Royale de Belgique – Bulletin de la Classe des Sciences – 5e Série. N. (1979). 65:274–92. doi:10.3406/barb.1979.58521
CrossRef Full Text | Google Scholar
39. Marshall, AW, and Olkin, I. Families of multivariate distributions. J Am Stat Assoc (1988). 84:487–93.
Google Scholar
40. Johnson, ME. Multivariate statistical simulation. New York: Wiley (1987).
Copulas for Finance a Reading Guide and Some Applications
Source: https://www.frontiersin.org/articles/642210
0 Response to "Copulas for Finance a Reading Guide and Some Applications"
Post a Comment